System Overview
Snowpack is a control plane for Apache Iceberg table maintenance. It discovers tables through a PyIceberg catalog, analyzes their health using Iceberg metadata, and runs maintenance operations (rewrite, compact, expire, cleanup) through Spark via Kyuubi. All state lives in Postgres — there is no Redis, no in-memory queue, no sidecar cache.
Architecture diagram
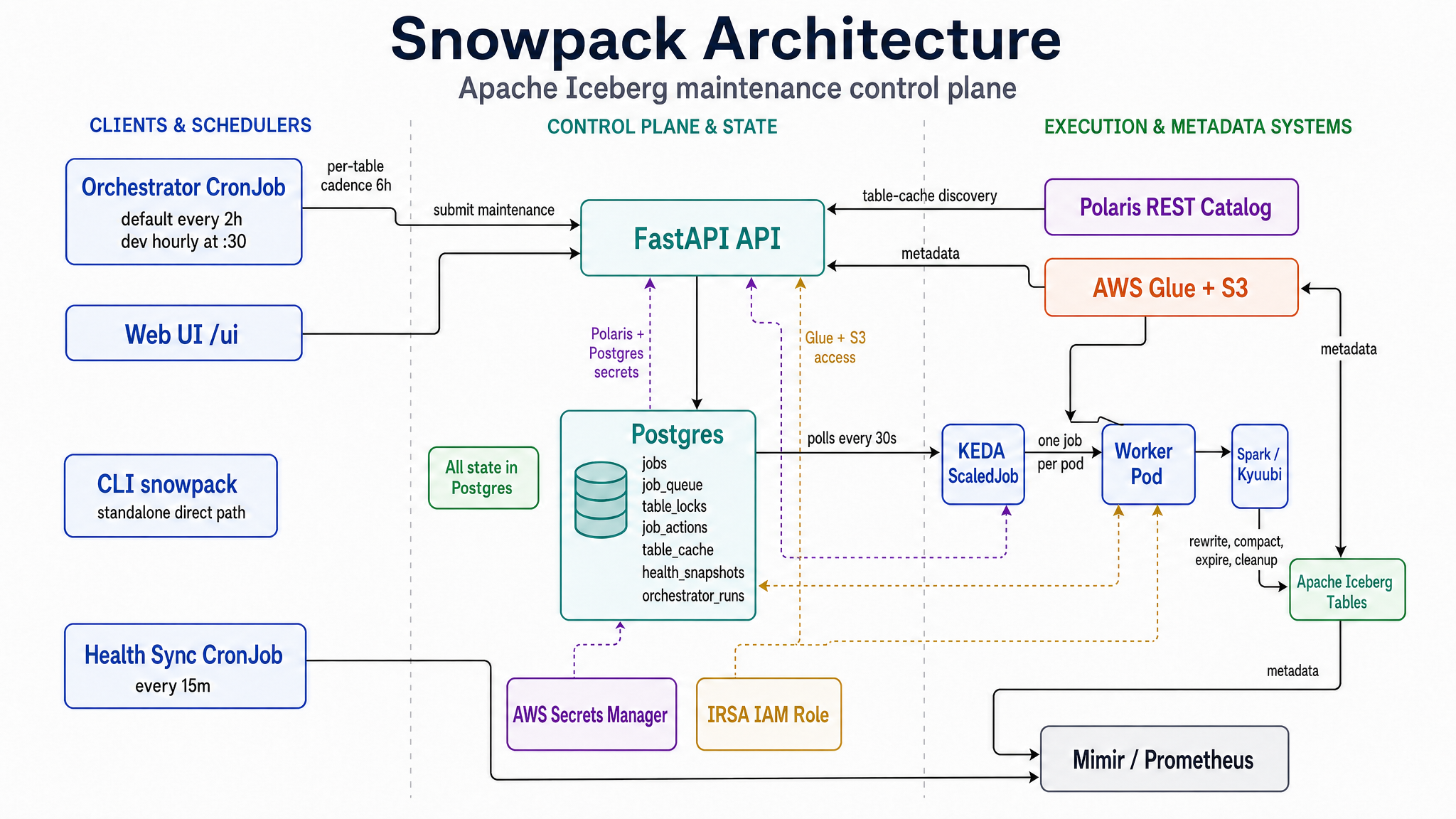
High-level topology
flowchart TD
UI["Web UI<br/>/ui Alpine.js SPA"] -->|HTTPS| API["FastAPI API<br/>snowpack-api, N=2<br/>/readyz /healthz"]
API -->|SQL| PG["Postgres<br/>jobs, job_queue, table_locks,<br/>job_actions, table_cache, health_snapshots"]
PG -->|"polled every 30s<br/>by KEDA postgresql"| KEDA["KEDA ScaledJob<br/>max replicas 5 (dev: 3)"]
KEDA -->|spawns| Worker["Worker Pod<br/>one job per pod"]
Worker -->|"Spark SQL<br/>actions"| Spark["Spark / Kyuubi<br/>Thrift JDBC"]
Spark --> Iceberg["Apache Iceberg<br/>tables on S3"]
Polaris["Polaris REST<br/>Catalog"] -.->|"table-cache<br/>discovery"| Iceberg
Glue["AWS Glue + S3<br/>PyIceberg metadata"] -.->|metadata| Iceberg
Worker -->|"health/job<br/>history"| PG
Orchestrator["Orchestrator CronJob<br/>default: every 2h<br/>dev: hourly at :30"] -->|calls API| API
HealthSync["Health Sync CronJob<br/>every 15m<br/>Glue/S3 → Postgres"] -->|writes| PG
HealthSync -->|"optional OTLP"| Mimir["Mimir / Prometheus"]
The standalone CLI (snowpack ...) bypasses the API queue and runs directly against the configured PyIceberg catalog and Spark / Kyuubi endpoint.
The orchestrator.schedule controls how often the CronJob checks tables. orchestrator.cadenceHours separately throttles how often a given table may be maintained. Current Helm values run the default chart every two hours (0 */2 * * *) and the dev environment hourly at :30 (30 * * * *); both keep the per-table cadence at 6 hours.
The API process also starts an in-process HealthSyncWorker when SNOWPACK_HEALTH_SYNC_INTERVAL_SECONDS > 0 (default 900 seconds). The Helm chart additionally defines health-sync-cronjob.yaml on the same 15-minute cadence. If the CronJob is intended to be the only health-sync owner, set the API env var to 0 or remove the in-process worker path.
Component inventory
Application (Python, snowpack/)
| Module | Responsibility |
|---|---|
api.py | FastAPI app — all HTTP endpoints + lifespan |
cli.py | Standalone snowpack CLI commands; bypasses the API queue |
worker.py | KEDA-invoked maintenance worker (one job/pod) |
jobs.py | JobStore — Postgres-backed queue + state (DL-197 fence) |
locks.py | TableLock — per-table ownership-checked lock |
table_cache.py | TableCache + TableCacheSyncWorker (atomic-swap refresh) |
history.py | HistoryStore — schema management + persistent reads |
backend.py | select_job_store / select_table_cache factory |
metrics.py | OTel/Prometheus gauges (queue depth, workers, etc.) |
config.py | Pydantic CompactionConfig — env-driven |
discovery.py | PolarisDiscovery — REST catalog table listing |
catalog.py | PyIceberg catalog factories (Polaris + Glue) |
analyzer.py | TableAnalyzer — produces HealthReport |
maintenance.py | MaintenanceRunner — executes one action via Spark |
spark.py | SparkQueryEngine — Thrift/Kyuubi wrapper |
service.py | CompactionService — request-scoped service composition |
orchestrator.py | Auto-submit maintenance based on health |
health_sync.py | Shared PyIceberg health precomputation worker |
health_sync_job.py | CronJob entrypoint for one health-sync cycle |
Infrastructure (Helm chart, charts/snowpack/)
| Template | Resource | Notes |
|---|---|---|
api-deployment.yaml | API pods (N=2) | Startup/Liveness/Readiness probes with 5s timeout |
api-service.yaml | LoadBalancer -> API | NLB with ACM-terminated TLS |
worker-scaledjob.yaml | KEDA ScaledJob | postgresql trigger, 30s polling, max 5 replicas by default / 3 in dev |
keda-postgres-auth.yaml | TriggerAuthentication | References the postgres secret |
postgres-secret.yaml | Secret | host/user/password (materialized from values) |
postgres-deployment.yaml + postgres-pvc.yaml + postgres-nlb.yaml | Internal Postgres | Used when postgres.internal.enabled=true |
orchestrator-cronjob.yaml | CronJob | Default every 2h; dev hourly at :30; calls API to submit jobs |
health-sync-cronjob.yaml | CronJob (every 15m) | Writes health_snapshots; dev concurrency 2 |
irsa.yaml | ServiceAccount + IRSA | IAM role for S3 / Glue access |
_helpers.tpl | Helpers | snowpack.postgresDatabase, snowpack.postgresSslMode |
Provisioning (Terraform, terraform/snowpack-api/)
The active dev root is terraform/snowpack-api/env/dev/main.tf. It provisions what Helm cannot: the AWS IAM role (IRSA), the Secrets Manager entry for the Postgres password, and the helm_release resource that applies charts/snowpack with values-dev.yaml. The chart version + values are the trigger for Terraform to re-apply.
Authentication and secrets
Two secrets are managed in AWS Secrets Manager and injected into pods via Helm set_sensitive blocks — never hardcoded in values files:
| Secret | Secrets Manager ID | Consumer |
|---|---|---|
| Polaris service principal | {env}/polaris/snowpack-principal (JSON: client_id, client_secret) | API + Workers (injected); API table-cache discovery uses it |
| Internal Postgres password | generated by Terraform (random_password) | API + Workers |
Polaris OAuth2 flow
Snowpack uses PyIceberg’s REST catalog with OAuth2 client credentials — credential = "{client_id}:{client_secret}" and scope = PRINCIPAL_ROLE:ALL. PyIceberg handles the token exchange and caching. The PolarisConfig validator rejects half-configured deploys: if uri is set, both credential fields must also be set.
Injection path: Secrets Manager -> Terraform data.aws_secretsmanager_secret_version -> helm_release.set_sensitive -> SNOWPACK_POLARIS_* env vars on pods -> Pydantic PolarisConfig. When polaris.uri is empty, create_iceberg_catalog falls back to Glue.
IRSA for Glue/S3
AWS access (Glue, S3) uses IRSA — the service account assumes aws_iam_role.snowpack via OIDC, no static AWS credentials.
Current catalog/metadata split
- TableCacheSyncWorker calls
create_iceberg_catalog; in dev this uses Polaris REST because Terraform setspolaris.uriand credentials on API pods. - /tables/{db}/{table}/health,
worker.py, and the health analyzer load Iceberg metadata through Glue/S3 viacreate_glue_catalog. - health-sync-cronjob.yaml currently passes Glue settings but not Polaris settings, so the CronJob discovers and analyzes through Glue. The shared
HealthSyncWorker.run_oncecan use Polaris for discovery if those env vars are supplied.